1 • Smart Cloud Kitchen & Rider Dispatch
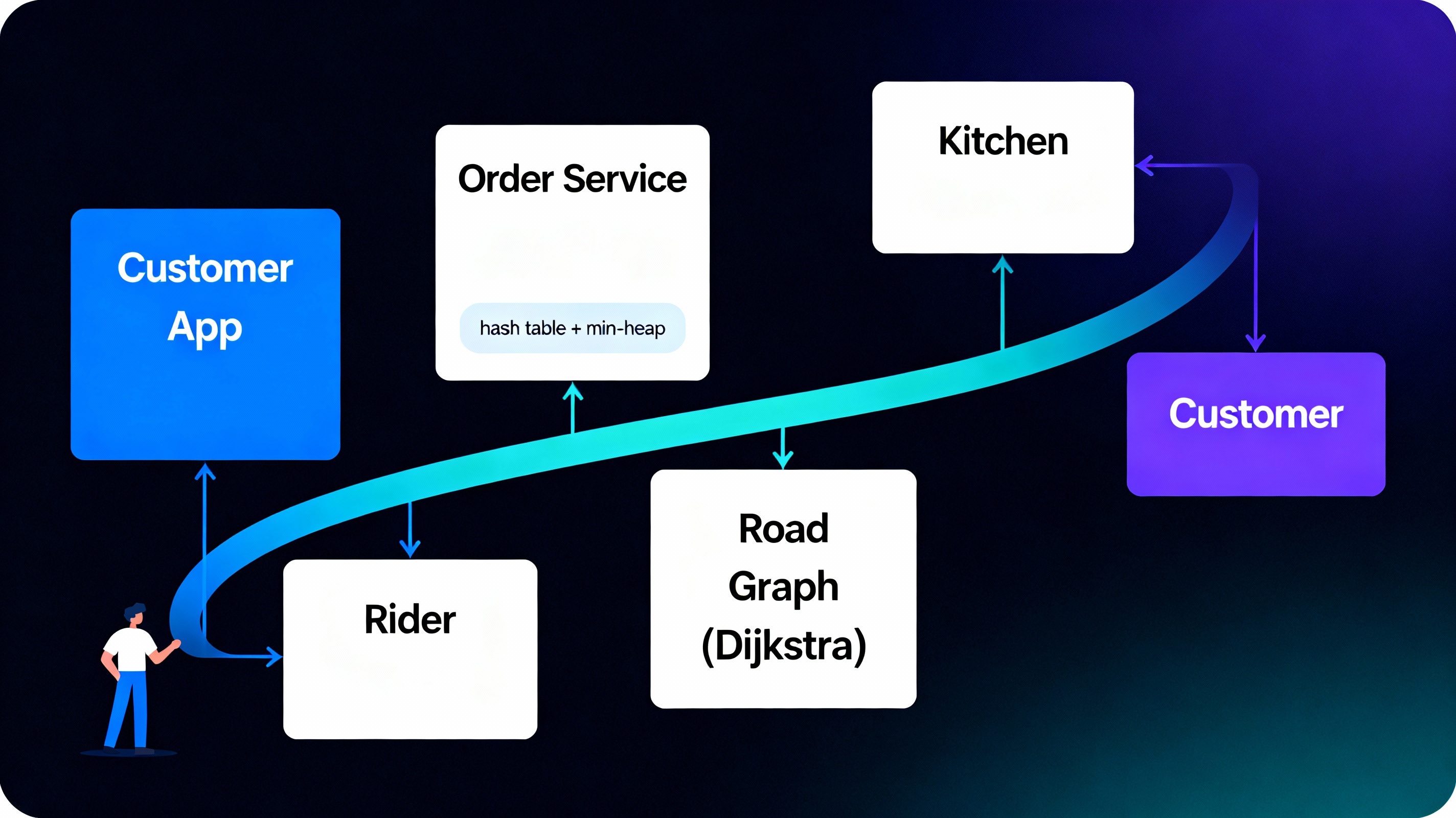
The cloud kitchen receives a continuous stream of food orders from different localities in Arohanagara and must decide which order to prepare and dispatch first, and which rider should take it. Orders and menu items are stored in hash tables for O(1) access by order ID and dish code, while all active orders enter a min-heap keyed by promised delivery time and penalty for delay. The city road network is modelled as a weighted graph; Dijkstra’s algorithm from the kitchen node estimates minimum travel times to each customer, and the system combines this with heap priority to select the next order–rider pair. This design keeps lookups constant-time, dispatch decisions logarithmic in the number of active orders, and overall delivery delay close to optimal.
Aligned SDGs: SDG 2 – Zero Hunger, SDG 11 – Sustainable Cities and Communities
Data Structures: de>unordered_map, de>priority_queue, adjacency list — Algorithms: de>Dijkstra
Orders → Hash & Heap → Dispatch Queue
City Graph → Dijkstra → Rider Path
2 • Supermarket Dynamic Pricing Engine
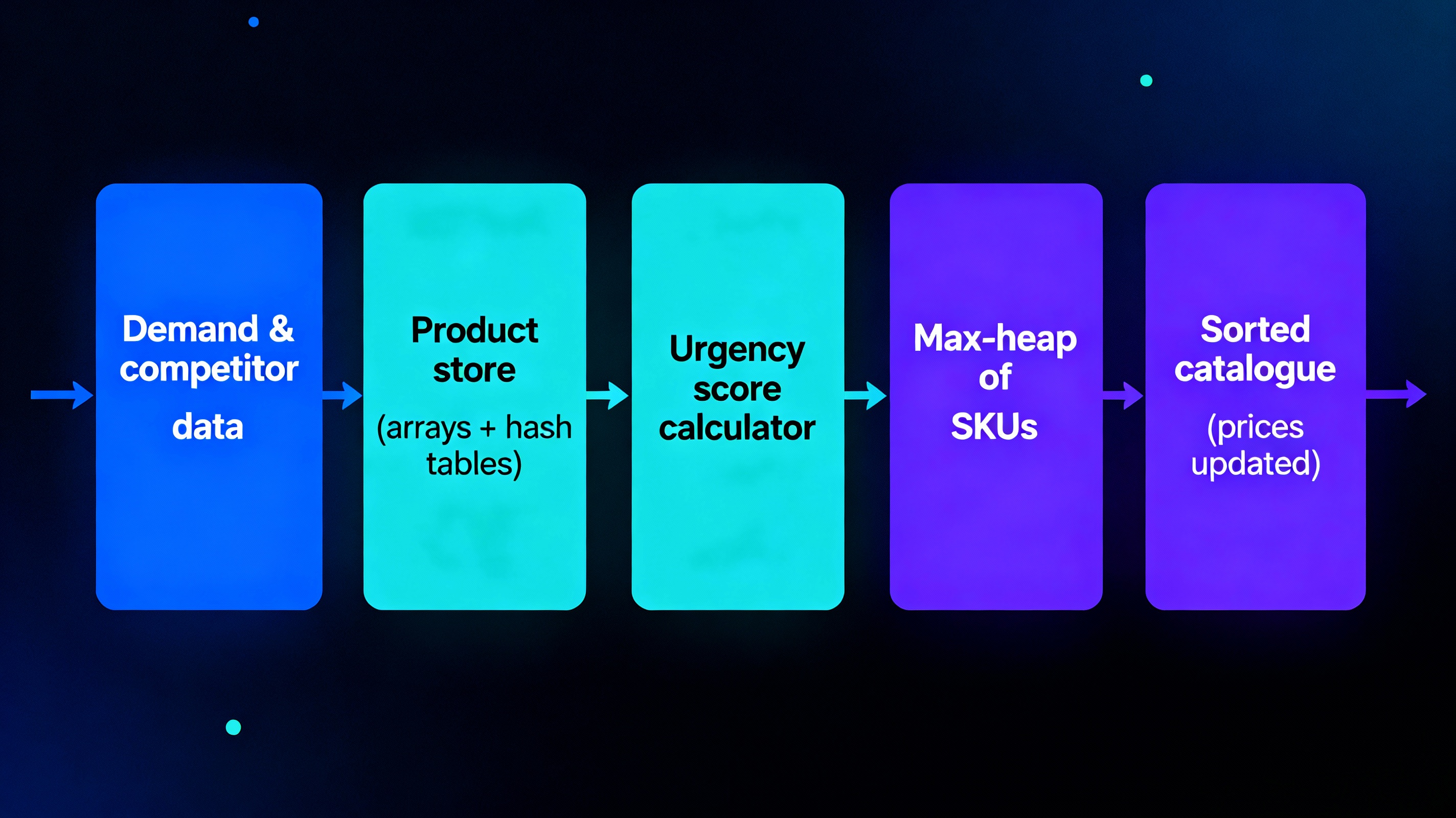
A large supermarket in Arohanagara wants prices that react to demand, competitor moves and stock levels instead of staying static for the whole day. Product master data and historical demand are stored in arrays and hash tables so each SKU can be updated in constant time by its ID, while periodic pricing runs recompute a combined “urgency score” from these signals. Candidate items are pushed into a max-heap to quickly surface products that most urgently need repricing, and the final catalogue is ordered with an \(O(n \log n)\) sort so high-urgency, high-margin items float to the top. This pipeline gives predictable performance even when the supermarket scales to thousands of SKUs.
Aligned SDGs: SDG 12 – Responsible Consumption and Production, SDG 2 – Zero Hunger
Data Structures: de>vector, de>unordered_map, priority_queue — Algorithms: de>std::sort
SKUs → Arrays / Hash → Dynamic Price
Demand → Heap → Top-k Products
3 • Automated Billing Code Matching & Fraud Detection
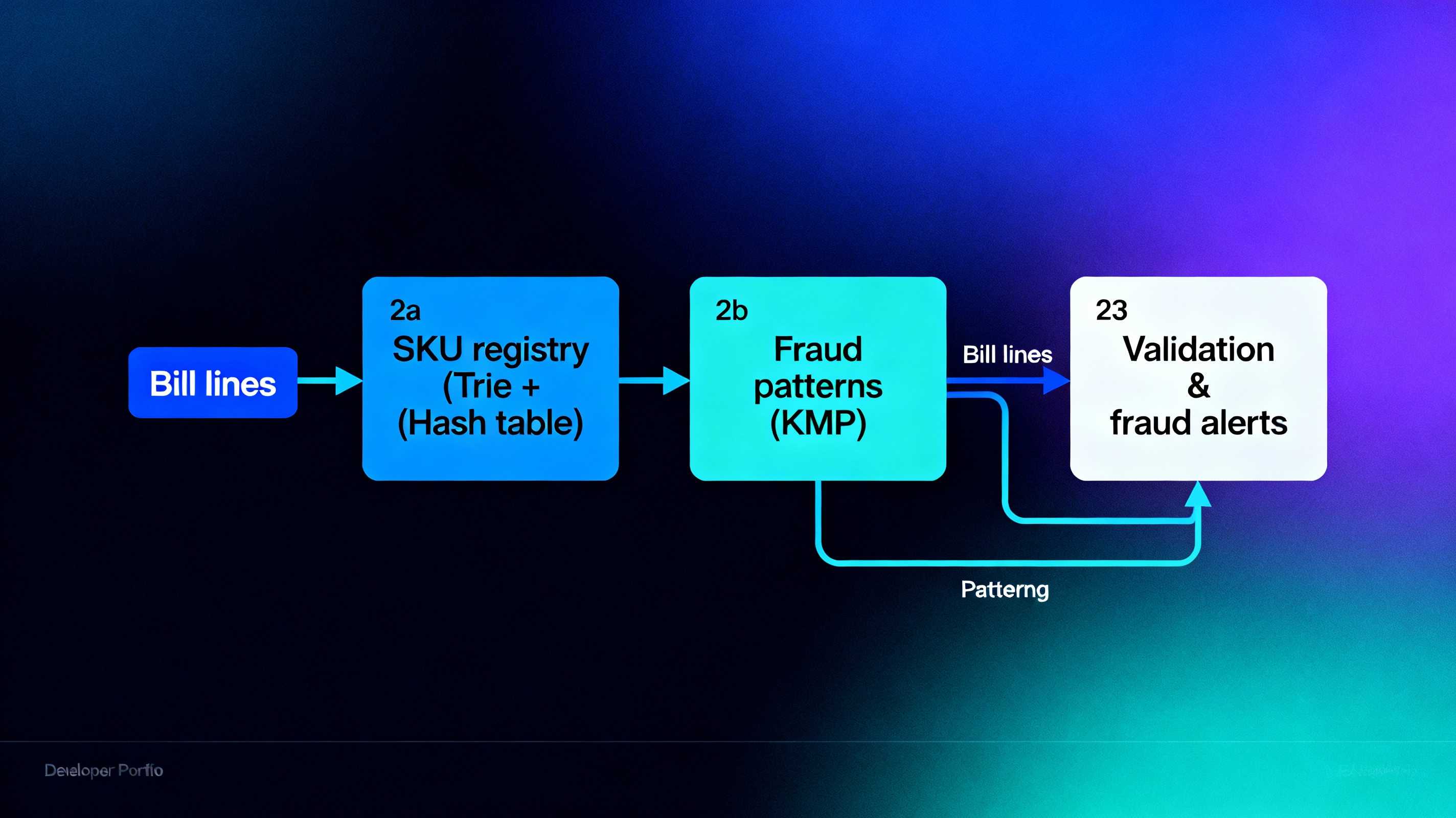
Retailers often generate long bills where manual verification of every line item is error‑prone and can hide fraud. The system loads the authorised SKU registry into both a Trie (for fast prefix and code validation) and a hash table keyed by SKU so that each bill line can be checked in O(1) or O(k) time. As descriptions and notes are streamed, a Knuth–Morris–Pratt matcher scans the text for blacklisted phrases and suspicious patterns without backtracking over characters. Together, these structures enforce that every billed code matches a known product and that risky textual patterns trigger alerts while still keeping per‑bill processing nearly linear in total characters.
Aligned SDGs: SDG 16 – Peace, Justice and Strong Institutions, SDG 9 – Industry, Innovation and Infrastructure
Data Structures: de>Trie, de>unordered_map, vector — Algorithms: de>KMP string matching
Bill Lines → Trie / Hash → Code Check
Text → KMP → Fraud / Anomaly Flags
4 • Supplier–Buyer Allocation Platform (B2B Matching)
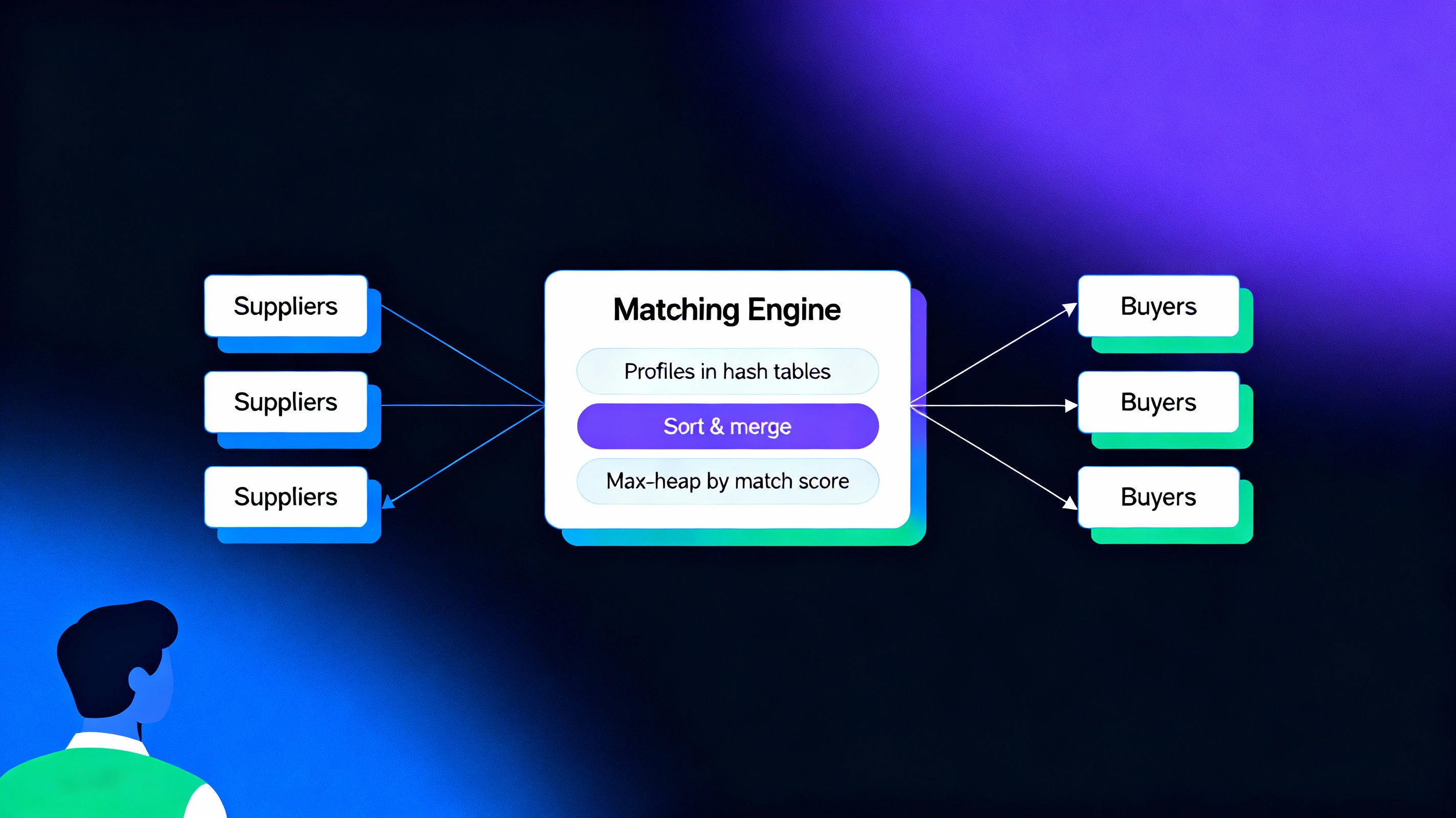
Small manufacturers and retailers in Arohanagara need a fair way to form supply contracts where both sides have constraints on price, capacity and quality. Supplier and buyer profiles are stored in hash tables keyed by ID, while vectors of structs capture bids and offers with ratings and price ranges. For each buyer, compatible suppliers are ranked using de>std::sort and a custom Merge Sort to handle different sorting keys, and a max‑heap over “match score” supports greedily popping the best remaining pair. This greedy but explainable allocation runs in \(O(n \log n)\) and produces high‑quality one‑to‑one matches for the current batch.
Aligned SDGs: SDG 8 – Decent Work and Economic Growth, SDG 9 – Industry, Innovation and Infrastructure
Data Structures: de>unordered_map, de>priority_queue, vector<Supplier> — Algorithms: de>std::sort, de>Merge Sort, de>greedy matching
Suppliers × Buyers → Score Matrix
Scores → Max-Heap → Greedy Match Allocation
5 • Urban Event Ticketing & Crowd Flow Optimizer
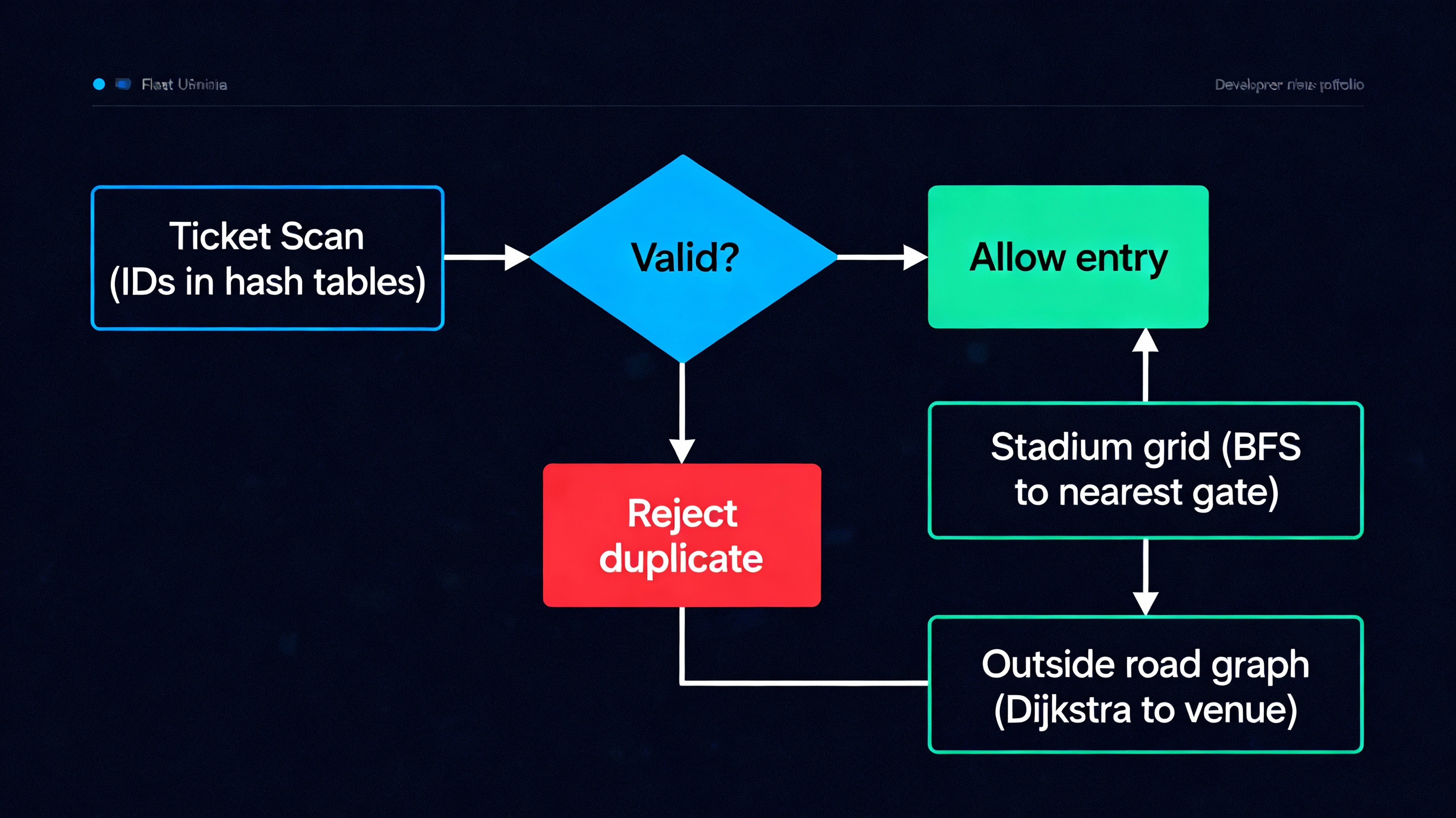
During big stadium events, organisers must block duplicate tickets and ensure crowds move safely to the nearest exit without creating jams. Ticket IDs and their status are stored in hash maps and hash sets so that every scanned ticket can be validated or rejected in expected O(1) time. Inside the stadium, seating and corridors are modelled as a 2D grid where BFS finds the shortest safe path from a seat block to an exit gate; outside, a weighted road graph represents different routes and Dijkstra’s algorithm computes least‑cost paths from parking or metro points to the venue. This integration of hashing, BFS and Dijkstra supports both security and smooth crowd movement.
Aligned SDGs: SDG 3 – Good Health and Well-being, SDG 11 – Sustainable Cities and Communities
Data Structures: de>unordered_set, de>unordered_map, 2D char array, de>adjacency list — Algorithms: de>BFS, de>Dijkstra
Ticket ID → Hash Tables → Valid / Duplicate
Stadium Grid → BFS → Nearest Gate Path
Road Graph → Dijkstra → Optimal Entry Route
6 • Government Document Authentication
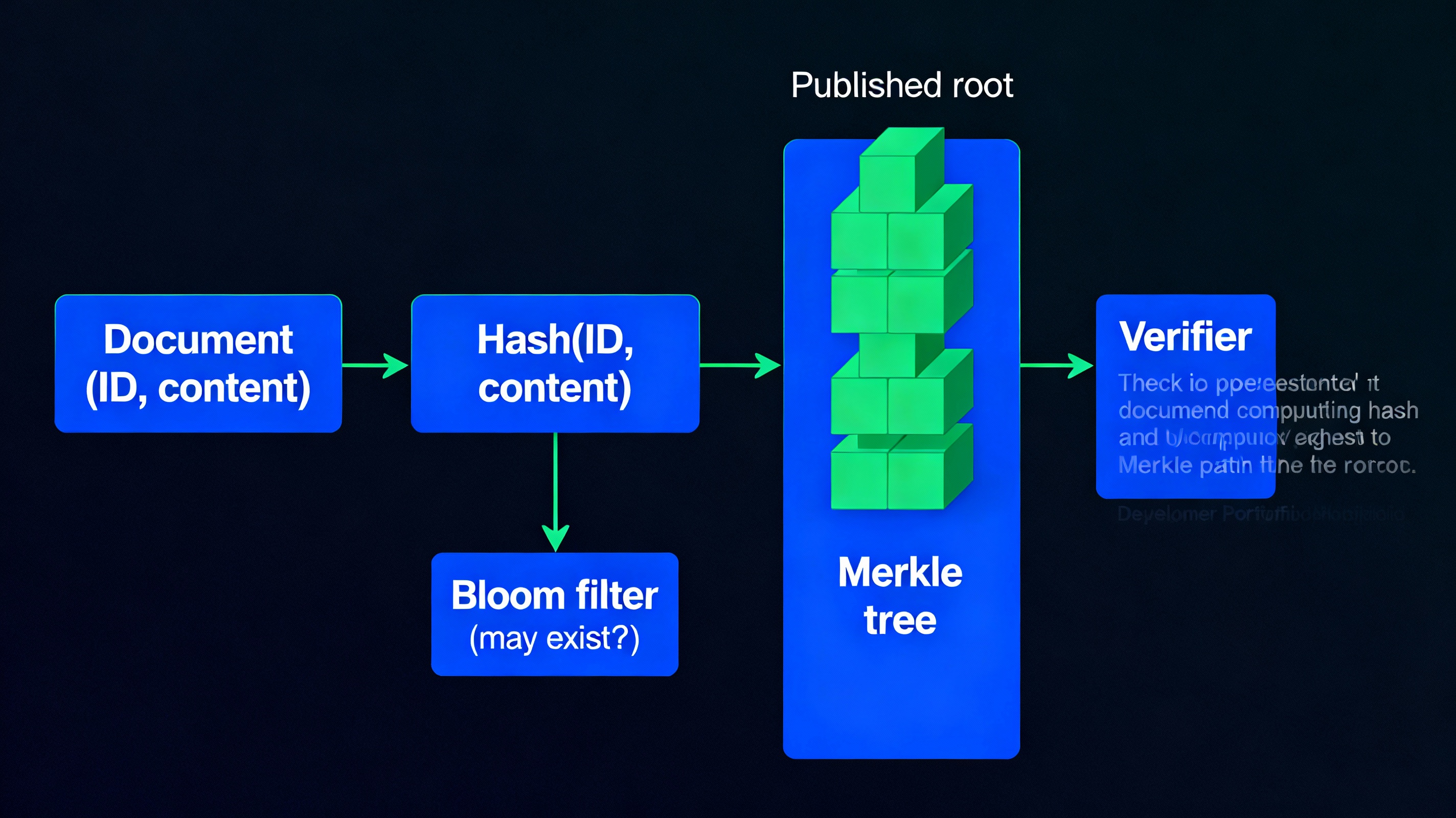
Government departments issue thousands of digital certificates such as caste, income and residence, and citizens or agencies must be able to verify authenticity without contacting the server each time. Each document’s ID and content are hashed and the ID is inserted into a Bloom filter so that verifiers can quickly do a “may exist / definitely not” check before any heavier work. All document hashes are organised into a Merkle tree, and only the Merkle root is periodically published; a presented certificate carries its own hash and Merkle path, and verification recomputes the path to recover the root and compare it with the trusted value. This design gives compact proofs, logarithmic verification time and strong tamper evidence.
Aligned SDGs: SDG 16 – Peace, Justice and Strong Institutions, SDG 9 – Industry, Innovation and Infrastructure
Data Structures: de>vector<Document>, de>BloomFilter, MerkleTree — Algorithms: de>string hashing, de>Bloom filter membership, de>Merkle proof verification
Doc(ID, Content) → Hash → Leaf
Leaves → Merkle Build → Root
ID → Bloom → Maybe → Verify Proof vs Root
7 • Government Complaint Routing
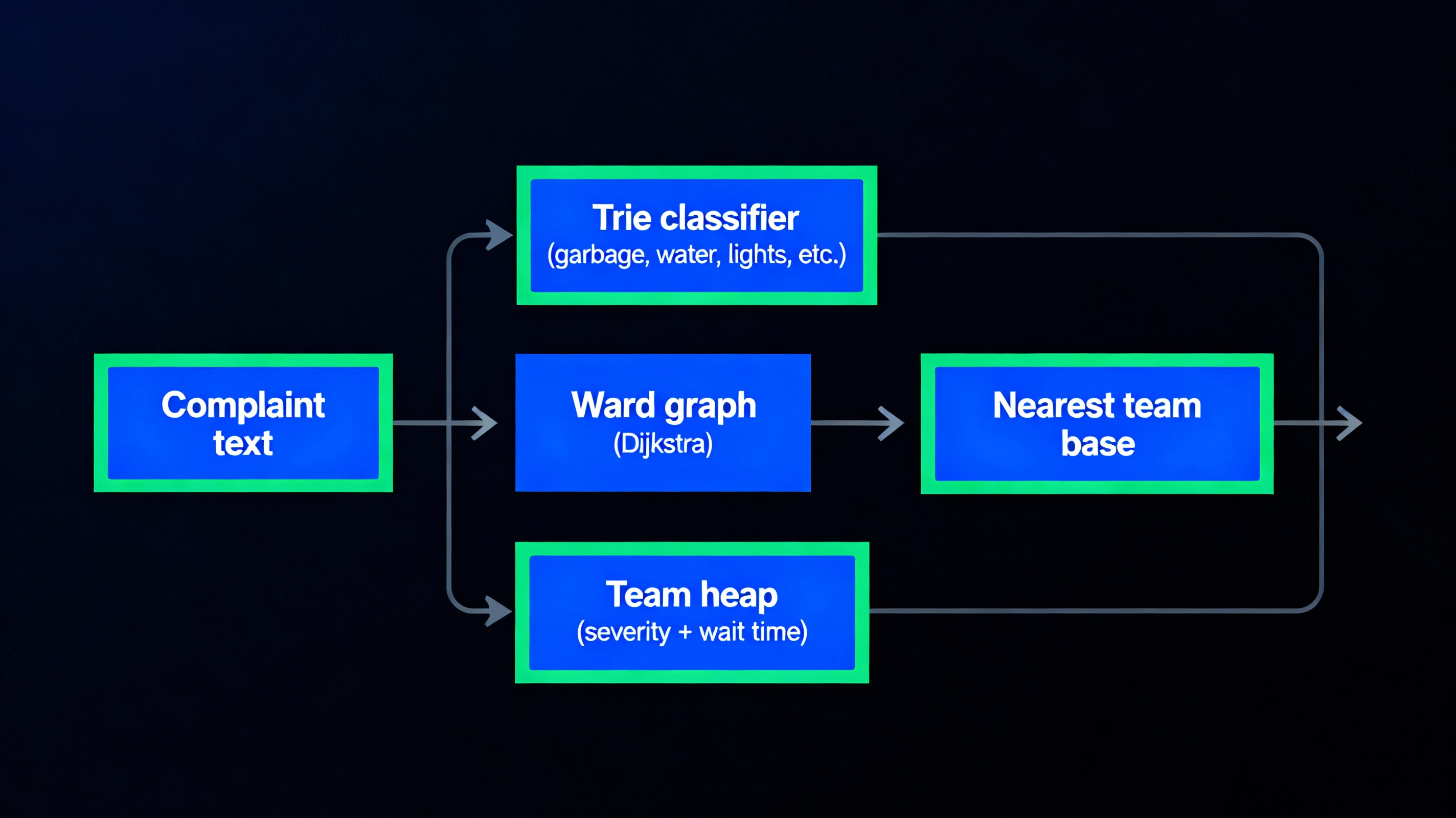
Citizens submit complaints about garbage, streetlights or water leakage using free‑text descriptions and approximate locations, and the municipality needs to route them efficiently to the right team. A Trie built from domain keywords maps noisy text into complaint types, while hash tables store ward information, team skills and bases for quick lookup. The ward connectivity graph is weighted by travel time; Dijkstra’s algorithm from the complaint location finds the nearest capable team base, and each team maintains a max‑heap of complaints ordered by severity and waiting time. This ensures both geographically efficient routing and fair prioritisation of the most urgent issues.
Aligned SDGs: SDG 11 – Sustainable Cities and Communities, SDG 16 – Peace, Justice and Strong Institutions
Data Structures: de>Trie, de>unordered_map, priority_queue, de>adjacency list — Algorithms: de>Dijkstra
Complaint Text → Trie → TypeTag
Ward Graph → Dijkstra → Nearest Team Base
Team → Priority Heap → Service Queue
8 • Smart Agriculture — Irrigation Network Planning
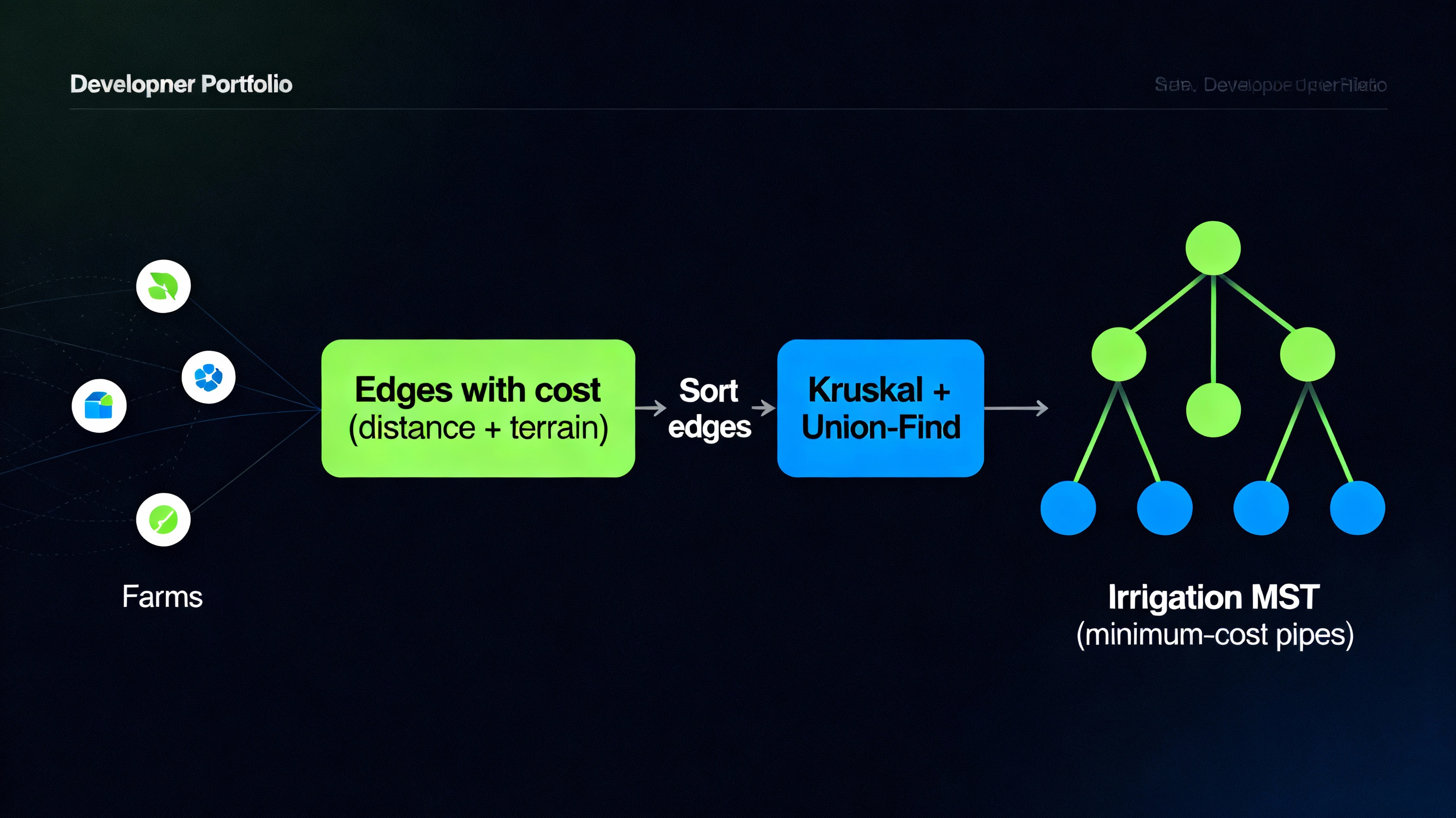
Farmer clusters around Arohanagara want to share a common irrigation backbone so that water from a source can reach every field at minimum construction cost. Each farm is treated as a node with coordinates and terrain type, and potential pipe segments between farms form weighted edges whose costs depend on distance and terrain penalty. These edges are sorted by cost and fed into Kruskal’s minimum‑spanning‑tree algorithm, which uses a Union–Find structure to keep track of connected components and avoid cycles. The resulting MST selects exactly those pipe links that connect all farms while minimising total pipeline length and therefore project cost.
Aligned SDGs: SDG 11 – Sustainable Cities and Communities, SDG 16 – Peace, Justice and Strong Institutions
Data Structures: de>vector<Farm>, de>vector<Edge>, de>UnionFind — Algorithms: de>Kruskal MST
Farm Coordinates → Dist & Terrain → Edge Costs
Edges → Sort + DSU → Irrigation MST
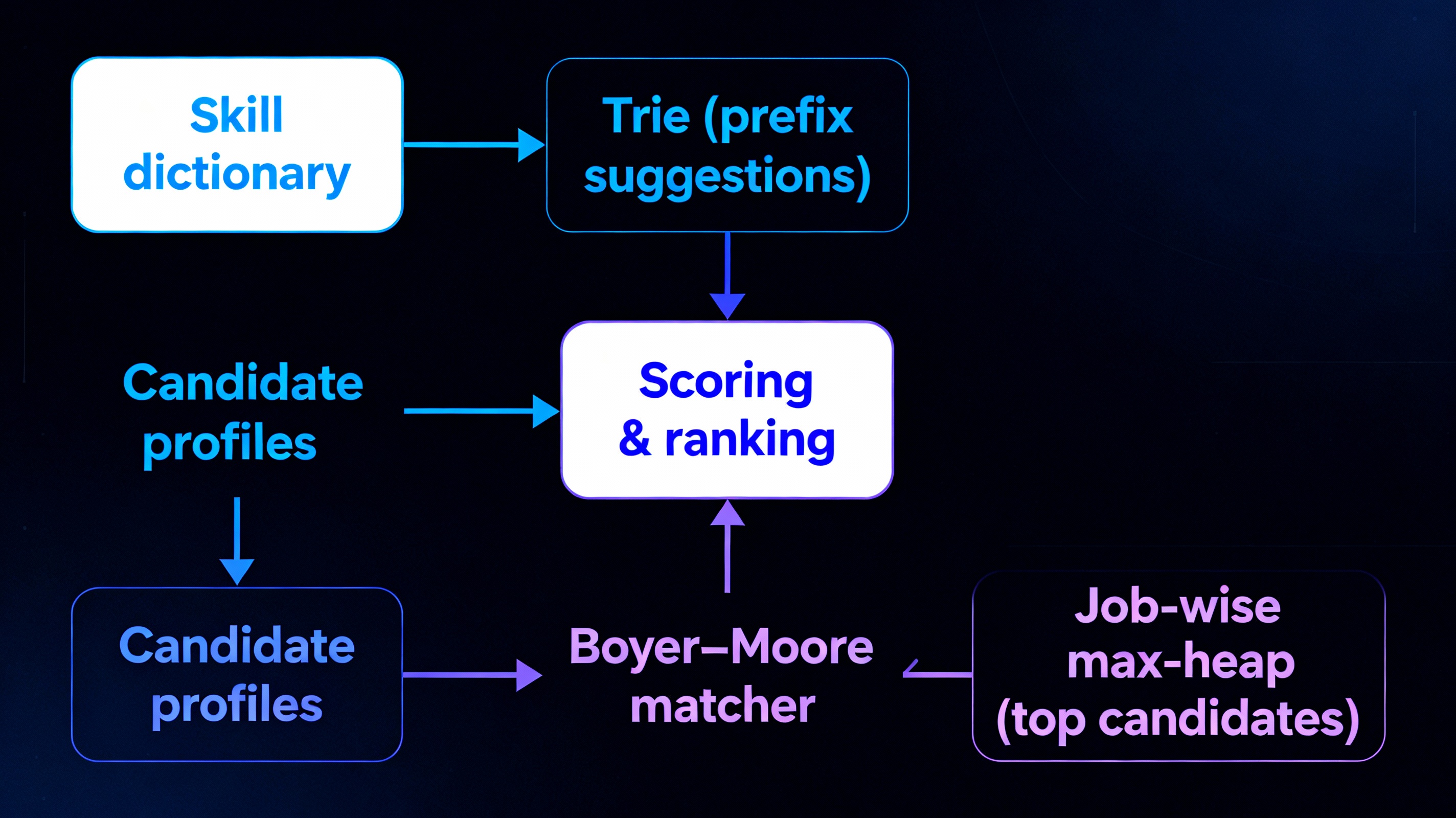
9 • Citywide Job & Skill Matching Portal
Job‑seekers and employers in Arohanagara specify skills mostly in free text, which makes exact matching difficult. A Trie built over the skill dictionary powers prefix‑based suggestions as the user types, while candidate and job profiles are stored in hash maps and vectors. When a job specifies a required keyword, Boyer–Moore pattern matching scans candidate descriptions to detect that exact skill efficiently, and for each job a max‑heap ranks candidates by a score that combines skill matches and geographic distance. Employers thus see the best‑fit candidates at the top of the heap with good performance even for large numbers of profiles.
Aligned SDGs: SDG 8 – Decent Work and Economic Growth, SDG 10 – Reduced Inequalities
Data Structures: de>Trie, de>unordered_map, priority_queue, de>vector — Algorithms: de>Boyer–Moore
Skill Dict → Trie → Prefix Suggestions
Candidate Text → Boyer–Moore → Skill Match
Job → Heap → Top-Ranked Candidates
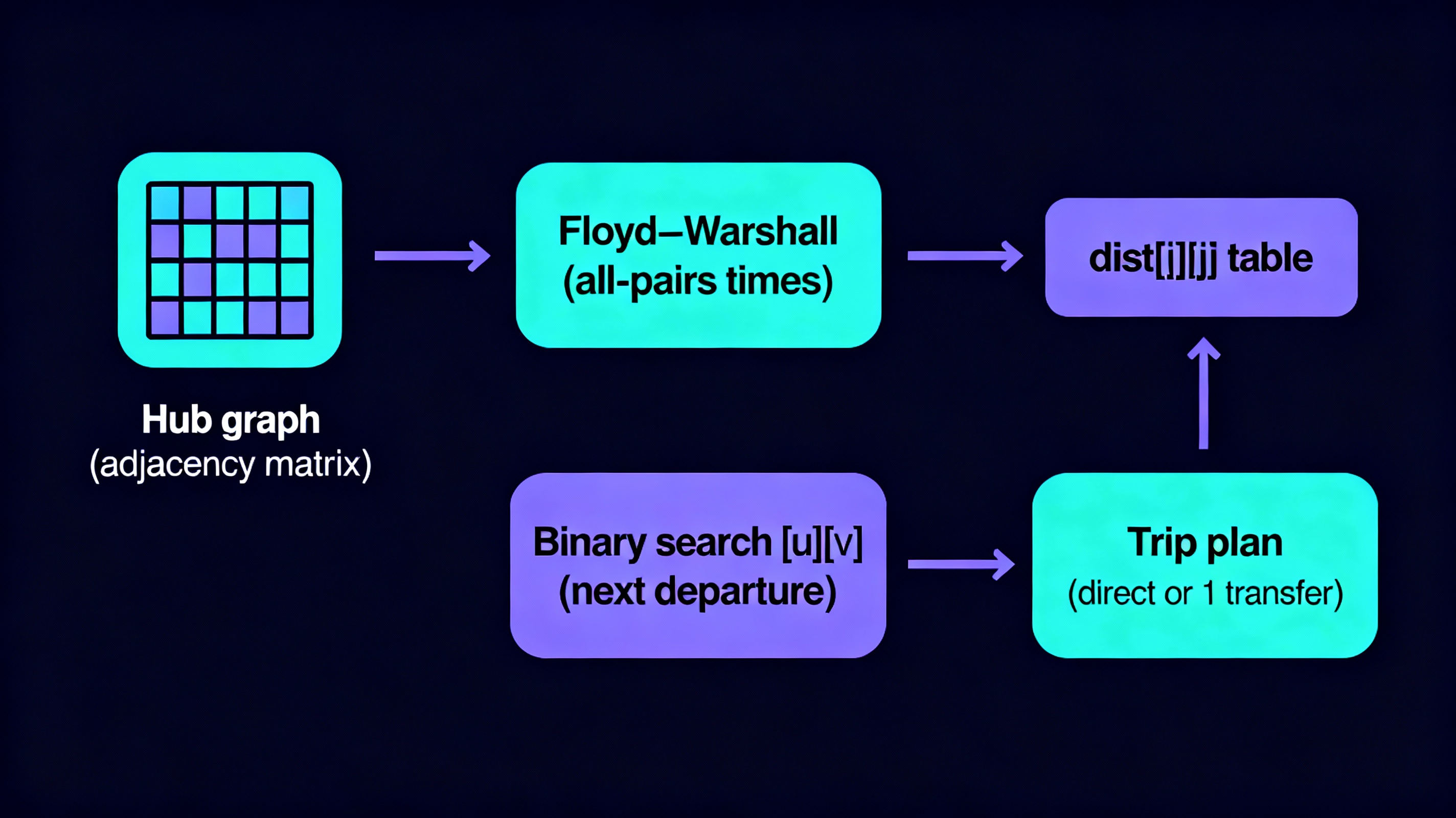
10 • Dynamic Public Transport Timetable & Transfer Optimizer
Arohanagara’s bus network has many hubs and routes, and passengers need fast answers for the quickest way to travel between any pair of stops at a given time. The system first builds a weighted adjacency matrix where each cell stores the in‑vehicle travel time between two hubs and runs Floyd–Warshall to precompute all‑pairs shortest travel times; later queries can then read them directly from the matrix. For each directed edge, departures across the day are stored in a sorted array, and given a desired start time, binary search finds the next feasible departure and, if needed, a single transfer that minimises arrival time. This combination of precomputation and logarithmic search yields real‑time journey planning with predictable performance.
Aligned SDGs: SDG 11 – Sustainable Cities and Communities, SDG 9 – Industry, Innovation and Infrastructure
Data Structures: de>adjacency matrix, de>vector<int> departures — Algorithms: de>Floyd–Warshall, de>binary search
Matrix → Floyd–Warshall → dist[i][j]
departures[u][v] → lower_bound → Next Departure → Trip Plan (≤1 transfer)